Experiments
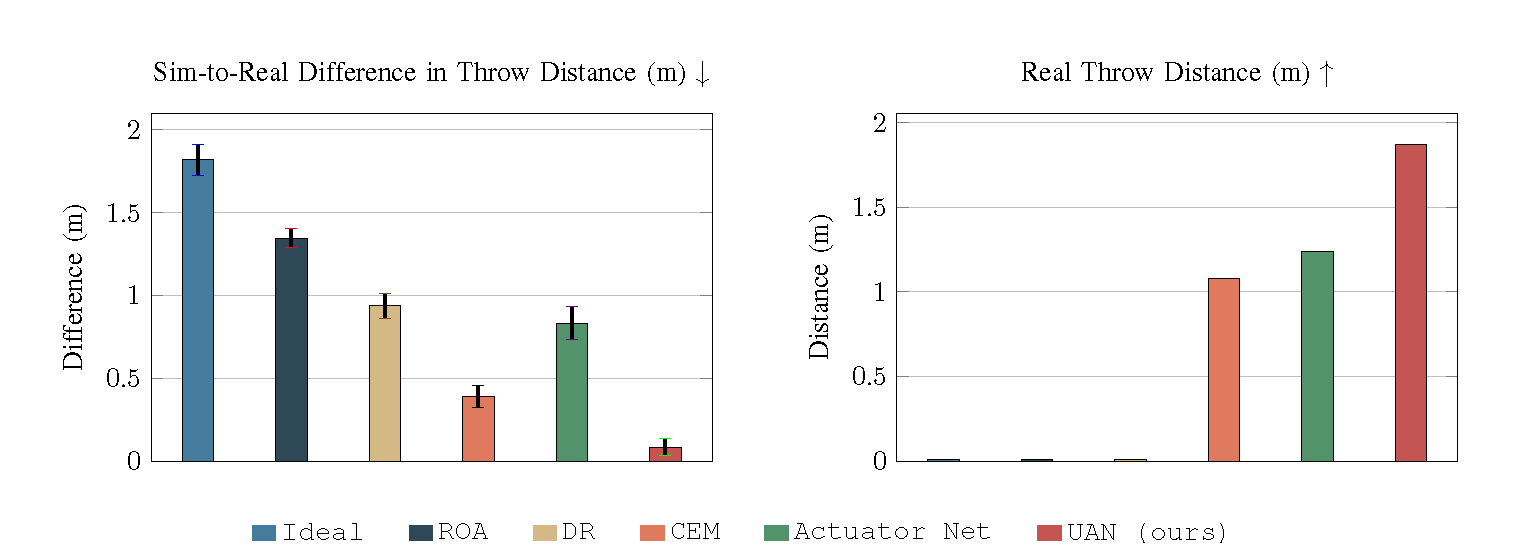
UAN calibration reduces the gap between simulated and real throwing performance.
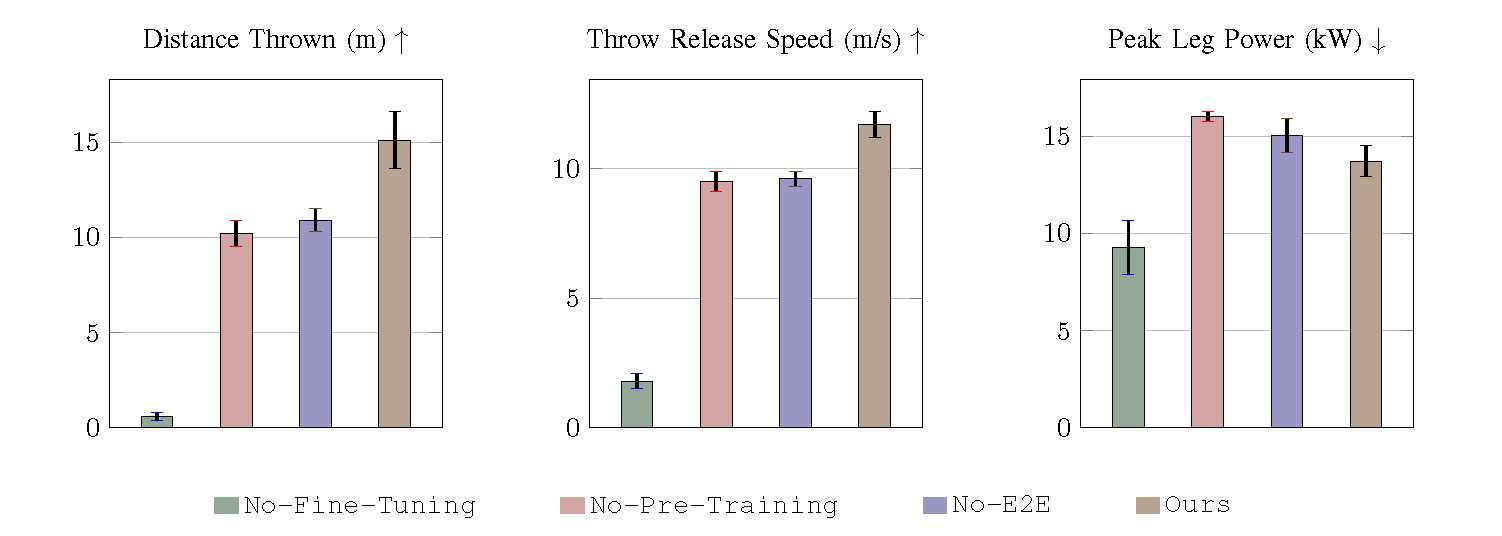
End-to-end athletic task policies outperform policies trained only with tracking rewards. However, we find that a pretraining stage based on tracking rewards benefits the final performance by assisting exploration.
This video shows simulated and real robot behaviors side by side, highlighting our good sim‑to‑real transfer.
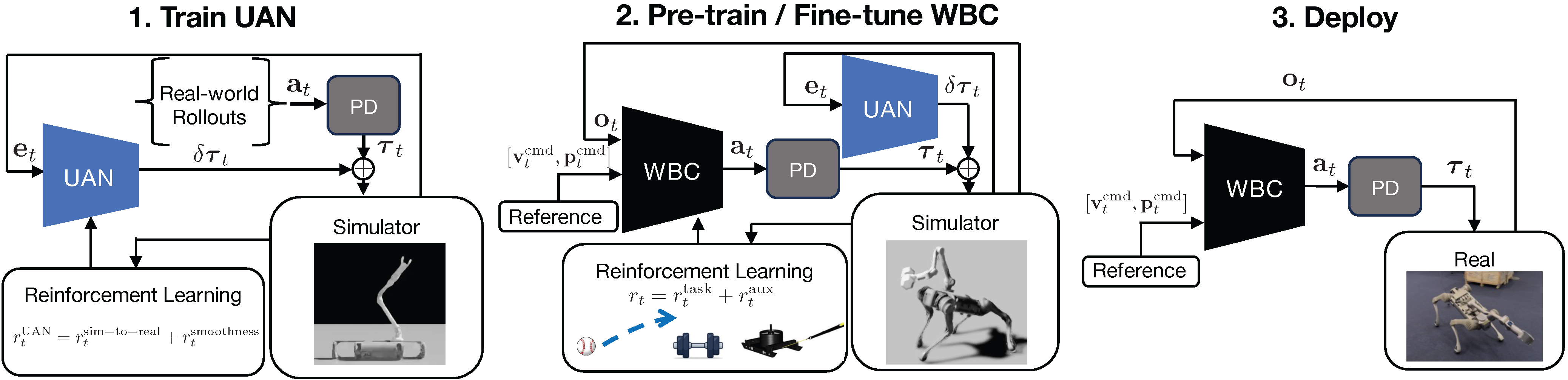
Architecture: UAN training, WBC pre‑training, fine‑tuning, then deployment.